A few weeks ago, I came across Anil Dash's article about the Artemis moon mission photos and Flickr. It's the perfect storm of my interests: creative commons licensing, long-term software sustainment, and cool spaceships. I discovered it thanks to a custom Bluesky feed I built.
In a radical act of malleable software, Bluesky has unbundled the algorithm from the client. Anyone can publish their own feed! Mine is written in Go, using text embeddings and a linear regression model trained on my past likes.
A sample of posts curated by my custom Bluesky feed.
Owning my feed algorithm taught me a few surprising things. I learned that likes are often social gestures and I needed to deprogram myself on that. I learned why big platforms (YouTube, X, etc) downweight your follows/subscriptions and focus instead on your revealed preferences of past interactions.
But most of all I was delighted by how easy it was to create a feed that fit my needs exactly. After all, I have only one user (me) and there are no confounding incentives from the platform or its advertisers. The result was to triple my use of Bluesky over the last month.
What I want from a feed
I miss the glory days of Twitter, which for me was roughly 2014–2021.
At its best, Twitter was a social network for ideas. My interests are simple but pretty clear: design mockups and UI prototypes from my community, discussion of new dev tools and practices, and some weird stuff like EV and solar panel adoption. I rarely want to see anything about politics or food, and prefer to avoid most memes and influencer videos.
As more of the research and local-first community migrates to Bluesky, it has the potential to fill the same place as classic Twitter for me. But using Bluesky, I've found that the Follow feed gets stale pretty fast. On the other hand, the Discover feed shows me too much random/popular stuff that doesn't feel customized. For You is better, but weights who I'm following too heavily compared to my topic interests.
There's also SkyFeed Builder and Graze which let you set up regex rules and filters to generate your own feeds. But I know from past attempts that manual filter curation is too much work to maintain over time, as my interests drift in different directions. I want something that adapts to my preferences through use—that is, an algorithm like you find in X, YouTube, or Spotify.
Implementation
To build my feed, I'll borrow from the academic field of recommender systems, aka RecSys.
A recommender system is a prediction machine for what the user will interact with. Pinterest, LinkedIn, and many others have published on their approach to this. In RecSys, the training data is a positive set (what the user and their follow network have interacted with in the past) and a negative set (things they have probably seen, but not interacted with).
Bluesky's custom feed API is deeply refreshing after so many years of tightly coupled platforms (content, curation algorithm, client all in one). My custom feed is served by a Go server and a Postgres database deployed on Railway. It creates a candidate pool of posts (posts from people I follow, plus posts they have interacted with) and then uses a small model trained on my past interactions to score and rank posts.
The "cold start" problem
RecSys tells us that it's hard to offer useful recommendations to a new user. Without any interaction data, the new user just gets a generic list of popular/mainstream recommendations. As the user uses the product it can build up a taste profile and give more customized results.
I was able to cheat on this a bit because I'm already using Bluesky, so some usage history already exists for my user. My solution to the cold start problem is to bootstrap with a couple months of likes/replies/reposts from my Personal Data Server (PDS), and use that as the positive training set.
❯ go run . bootstrap adamwiggins.com
msg="fetched follows page" total=180
msg="fetching positive interactions" since=2026-03-31T05:17:58Z
msg="fetched likes" count=331
msg="fetched reposts" count=25
msg="negative sampling progress" follows_done=175 of=180 negatives_stored=650
follows=180 pds_resolved=180 engagements_seen=84230 retained_on_known_posts=783 dropped_off_set=83447 retention_pct=0.93 inserted=783
@adamwiggins.com
180 follows
May 26 going back 8 weeks:
384 interactions (331 like, 25 repost, 28 reply)
624 non-interacted posts within +/- 10 minutes
783 follow-network engagement rows (641 like, 142 repost)
Bootstrapping a training set at the CLI.
There's no great way to bootstrap the negative set, which are posts I saw but didn't interact with. I used the guesstimate of posts from people I'm following within +/- 10 minutes of a post I did interact with. This is temporary until I have real interaction data from the running feed.
Embeddings, features, and training
With a training set assembled, the software then computes:
- a text embedding for the post body
- training features like whether the post has a link, or how often I've interacted with this author's past posts in the past
- a computer vision caption of the first image attachment
The image caption is expensive compared to the text embedding. But it's important because I want to be able to tell apart (for example) UI mockups from travel photos.
❯ go run . train adamwiggins.com
msg="training set assembled" total=977 positives=353 negatives=624 interaction=353 impression=0 bootstrap_presumed=624 embedding_dim=1536 feature_dim=19
msg="train epoch" epoch=0 loss=0.2592
...
msg="train epoch" epoch=59 loss=0.1005
trained model id=1 for @adamwiggins.com (user_id=1)
training: 977 examples (353 positives)
sources: interaction=353 impression=0 bootstrap_presumed=624
eval: skipped (holdout=0)
final loss: train=0.1005
weights: 1555 dims (embedding=1536 + features=19)
Training a linear regression model.
The classifier model is based on the one I built for my email triage project, so you can read the ML technical details there.
The flywheel
With the bootstrap complete, the long-running server process can listen to the Bluesky firehose and start storing posts. I only keep posts and interactions from within my follow network, so storage needs are low: my first month of data was about 35k posts and 36k interactions.
Time to try it! I add the feed URL to my Bluesky client, and any time I refresh it hits my server to ask for a list of ranked posts to appear in the feed.
My feed in the Bluesky mobile app.
Accessing the feed records impressions of posts, so now I have a real negative set: posts I've scrolled past, but didn't interact with. That can be used for the next model training for a better result than the bootstrap guess at posts I may have seen.
❯ go run . feed adamwiggins.com
ranked feed for @adamwiggins.com (τ=6h, window=24h, half-life=6h, α=0.90):
0.0467 p=0.626 5 hours ago served 31 minutes ago
@simonwillison.net -> ... plus a bonus section of transcript from the Oxide and Friends 2026 predictio…
0.0413 p=0.098 5 hours ago served=never liked by @hyl.st
@bmann.ca -> Real time. We have some examples of this in the lab. It’s transcribing in real t…
A CLI debug tool that shows the feed with prediction scores, in-network likes, and other reasons why each item is included.
Once I trusted that the model produced good results, I configured it to auto-retrain every 15 interactions.
$ go run . models
ID Handle Trained Impressions Engaged
8 @adamwiggins.com 1 day ago 334 7
7 @adamwiggins.com 4 days ago 356 15
6 @adamwiggins.com 6 days ago 417 32
5 @adamwiggins.com 19 days ago 2186 78
4 @adamwiggins.com 28 days ago 1396 55
My model history, with auto-retrain starting recently.
I like the results
I immediately loved my new feed. Right at the top were great posts including Andy Matuschak's latest essay and the aforementioned post about Artemis and Flickr.
This is the reason I use social media—high quality, thoughtful posts by people in my professional community. And while I am following Andy and just hadn't seen his post, I am not following Anil—but the post was ranked highly by my custom feed as something many people in my network liked. That's the curation algorithm doing its thing.
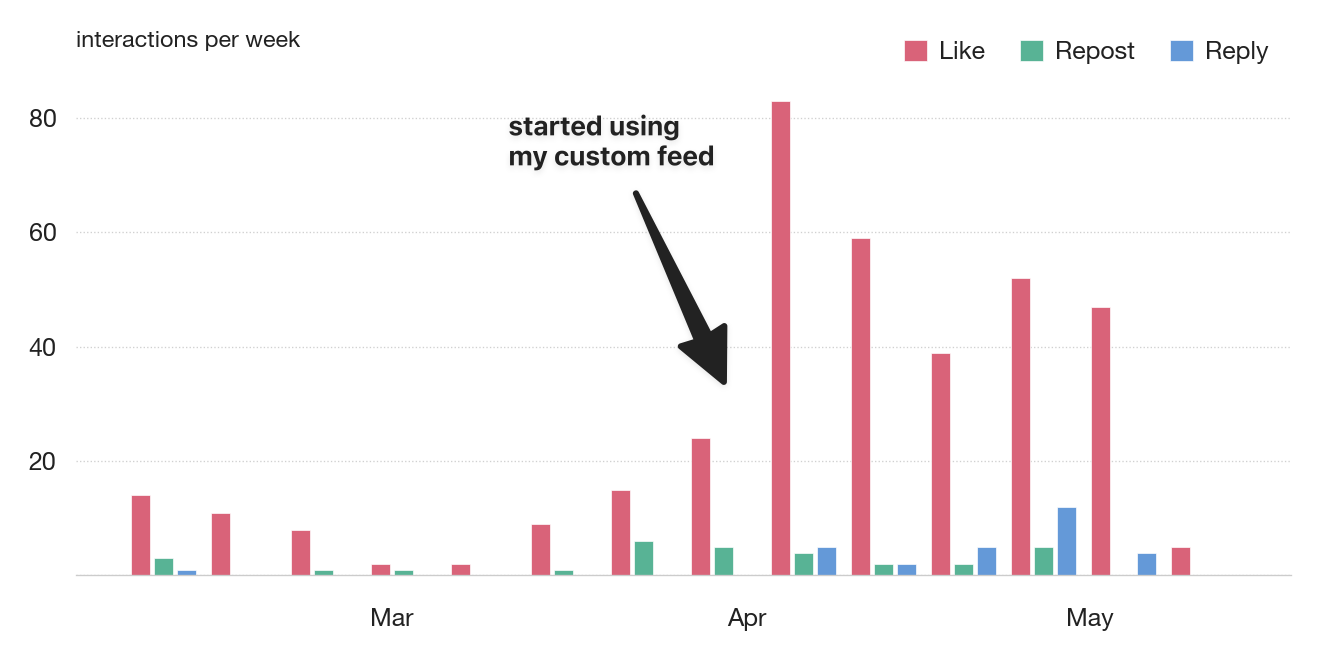
My Bluesky usage increased dramatically when I started using my custom feed.
Initially lots of likes as I tried to give the algorithm more signal, and then ongoing more reposts and replies—the latter reflects real community engagement.
My usage of Bluesky has increased substantially since then, not only reading but also replying and reposting. It feels good to have a social network of ideas again.
De-socializing likes
One surprising finding was how I think about when to click "like" on a post.
A complaint many people have about curation algorithms is they seem to ignore or barely weight your explicit preferences. Who you follow on X doesn't have much effect on the main feed—the algorithm explicitly pulls 50% of its candidate posts from outside your follow network. Similarly, subscribing to a channel on YouTube is, by itself, not enough to get the homepage to surface their latest video to you. This seems odd and many creators and audience members find it frustrating.
Having built a small recommender now, I see why this is actually correct for most people. Following and subscribing are heavyweight signals, and thus suffer from the same problem of manually tuning rules and filters. A user's behavior, especially as it changes over time, is a better signal for what the user wants to see.
I think of it like this: liking someone's posts a few times is an implicit follow. Ignoring their posts a few dozen times is an implicit unfollow.
The consequence, though, is that "social likes"—politeness, supporting a friend, acknowledging a reply—are confounders for my personal algorithm. So I'm now treating likes as less of a social gesture, and more of a note to my algorithm on what I want to see more of in the future.
Closing thoughts
Curation algorithms are everywhere now: they guide us to what we watch, what we read, what we buy. The optimistic view of this is that it enables the Long Tail of niche creators to find audiences. The pessimistic view is that it creates filter bubbles and political polarization.
I hope what I'm doing with my custom feed points toward a third way: channeling my computing values (data ownership, malleable software, user agency) into a truly personal feed, to have it curate the things I find productive for my life goals.
I'm delighted with my feed and am now using it daily. You can subscribe, but since it is trained on my preferences, it may not be that interesting for you. (You can DM or email me if you'd like me to train one for your handle.)
If I were to keep developing this project, the next obvious step would be to support new users without requiring a manual CLI bootstrap. And the current bootstrapping process is costly enough (~30 seconds of API calls and model training) that I'd probably want to switch over to a two-tower system, where each user's taste is stored as an embedding rather than a standalone model.
I also expect that with time I'll tire of the overfit / echo chamber effect of my current algorithm. The RecSys solution is to add "serendipity" by blending in say, 10% of posts from an explorer heuristic. Alternately I could fork the feed, keep the existing one as "don't-miss posts from my network," and add something else for serendipity when I get bored.
Having now applied this personal algorithm approach to two domains (email triage and Bluesky feeds) I'm curious to know if there are other suitable use cases out there. Feel free to get in touch if you're on a project that could benefit from a personal algorithm.